DataRobot 手把手教學:如何從其他專案調用 Blueprint(上)
Posted On 2021 年 8 月 26 日
本篇教學文章目的是為了驗證開發的資料壓縮演算法,是否達到與原始資料差不多的準確度,以及節省更多的訓練時間。接下來將使用數值型以及圖片型的資料,於 DataRobot 輸出適用於 Python 的 AutoML 最佳機器學習流程、演算法和超參數設定,並使用相關 API 完成數據之建模其建模過程較原始之 AutoML 速度較快且準確度相近。 
偉康科技提供以雲端服務、智能數據、資安技術為核心的數位轉型解決方案,協助攻克企業資料治理遇到的難題,如有需求歡迎 聯絡我們
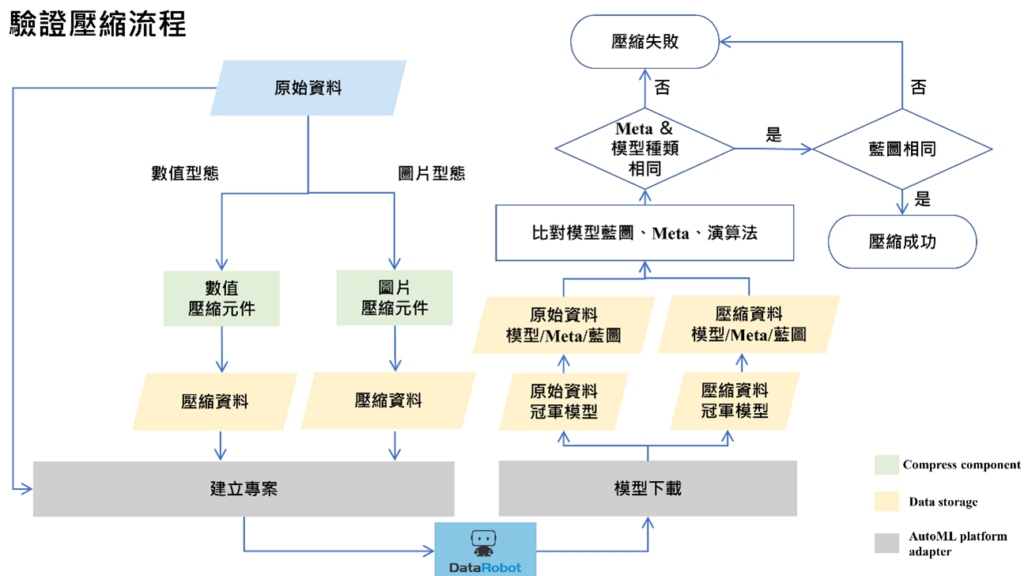
驗證壓縮流程
首先在原始資料進入 DataRobot 前需要判斷資料的型態,因應不同資料型態會有不同的資料格式需做處理。數值型為需要表格類的資料格式,如 csv, excel 等;而圖片資料須以將最外層資料夾命名為其對應的標籤並將所有資料夾封裝成壓縮檔格式上傳。 DataRobot 在建立專案以及訓練完模型後,會評比各模型並選出推薦的部屬模型,其模型的 Blueprint 為 AutoML 認為該資料應採取合適的資料前處理及其模型。接著將原始、各壓縮比的資料各自上傳至個別的專案進初步的處理。各專案會先進行最快速的 AutoML 訓練,並挑選出最推薦模型,再將各模型 Blueprint 做比較,如果資料處理流程以及模型 (及細部演算法) 皆為相同的話,則判斷為該壓縮演算法及其壓縮比率為可採用。
驗證壓縮流程圖
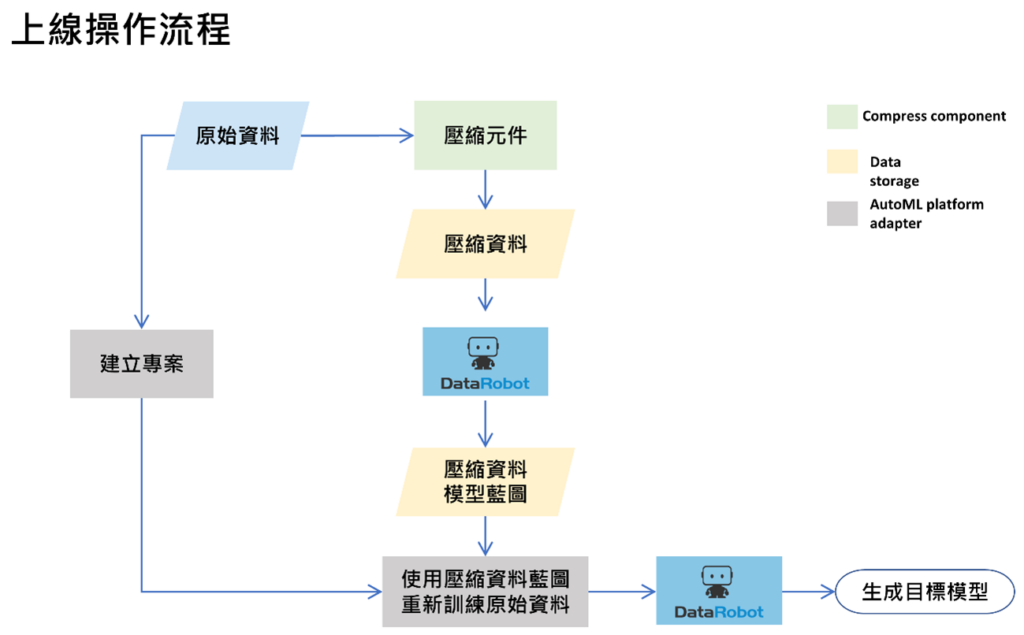
上線操作流程
確認壓縮比率的模型 Blueprint 與原始資料模型 Blueprint 一致後,會再另開新 Project 將原始資料上傳,並且透過 DataRobot 的 API 導入已訓練完的模型 Blueprint,再將原始資料進行 100% 全資料的重新訓練,最後產生目標模型。下圖為上線操作流程圖,後續的 API 操作會以這張流程圖作為一步步地介紹。
上線操作流程示意圖
DataRobot 術語說明
在 DataRobot 中有以下專有名詞,為方便後續驗證流程說明,在此做簡略介紹。從外到內依序為 (1) Project、(2) Model、(3) Blueprint。Project
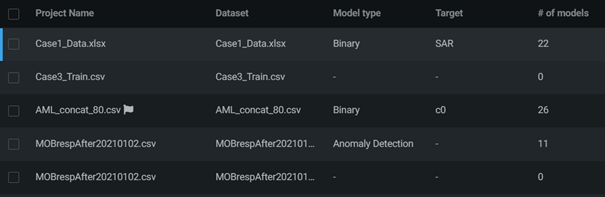
整個 Project 裡面會包含資料的操作、model 等等。為進行 AutoML 的最外層,所有操作皆以 Project 為基底進行,涵蓋了 model, Blueprint。 下圖為 DataRobot 裡的 Project列表示意圖。
DataRobot 裡的 Project 列表
Model
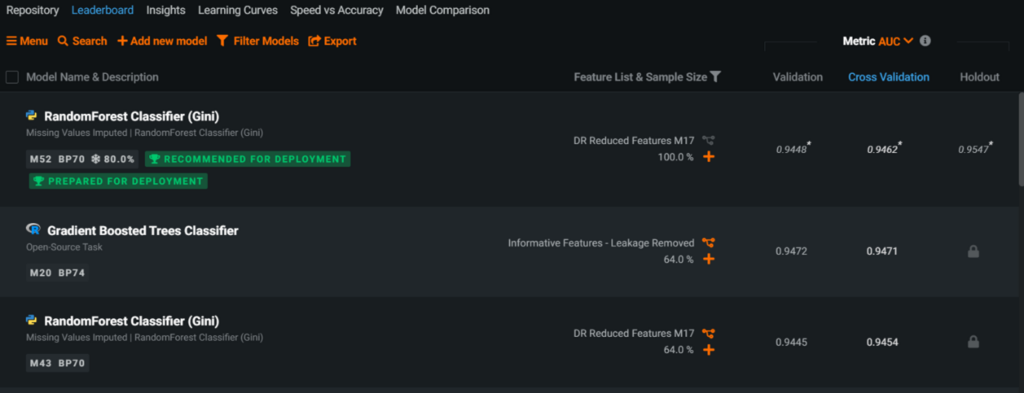
會有許多相同的 model 顯示,例如 XGBoost, RandomForest 等等。有些模型基底會為相同,但細部演算法描述會有差異。另須注意 model ID 為一個已訓練過的結果,並不是一個正在訓練的過程。下圖為 Project 裡的 model 列表示意圖。
Project 裡的 Model 列表
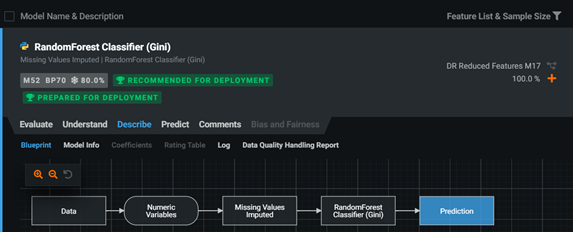
Blueprint
DataRobot 集合了許多經驗豐富的資料科學家,將每個 Model 根據不同資料類型還會設計出不同的資料前處理,也就是 Blueprint。下圖為 model 裡的 Blueprint 示意圖。
Model 裡的 Blueprint
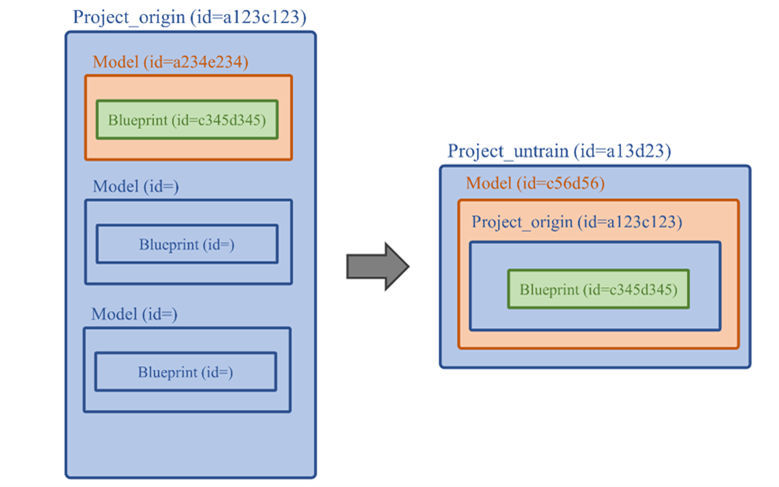
以下是 DataRobot 裡由大至小的劃分,將它想像成這樣 : [Project → [Model → Blueprint ], [Model → Blueprint ],….]。同樣的編號 (bp…) 以及描述的 blueprint 還是會有不同的地方 ( hyper parameters 等等)。所以這三個區塊都會有各自的 id 作為識別。 下圖為 DataRobot 調用其他專案 Blueprint 的示意圖。Project_untrain 若需調用其他專案的 blueprint 就得要同時指某個定 Project id 的某個 Blueprint。以此示意圖就是指定 Project id = a123c123 與及其 Blueprint id = 345d345。
未訓練專案調用已訓練專案的示意圖
DataRobot 手把手教學:如何從其他專案調用 Blueprint(下)
訂閱偉康科技洞察室部落格,掌握最新科技趨勢!
了解更多
DataRobot AutoML DataRobot MLOps偉康科技提供以雲端服務、智能數據、資安技術為核心的數位轉型解決方案,協助攻克企業資料治理遇到的難題,如有需求歡迎 聯絡我們