Greenplum主要特色概要

圖/文:Jeffery Su
Greenplum主要功能
圖片出處:Pivotal Greenplum
本文為簡短快速介紹 Greenplum 的功能概要,以及提供部分功能的官方連結,供讀者快速了解 Greenplum。
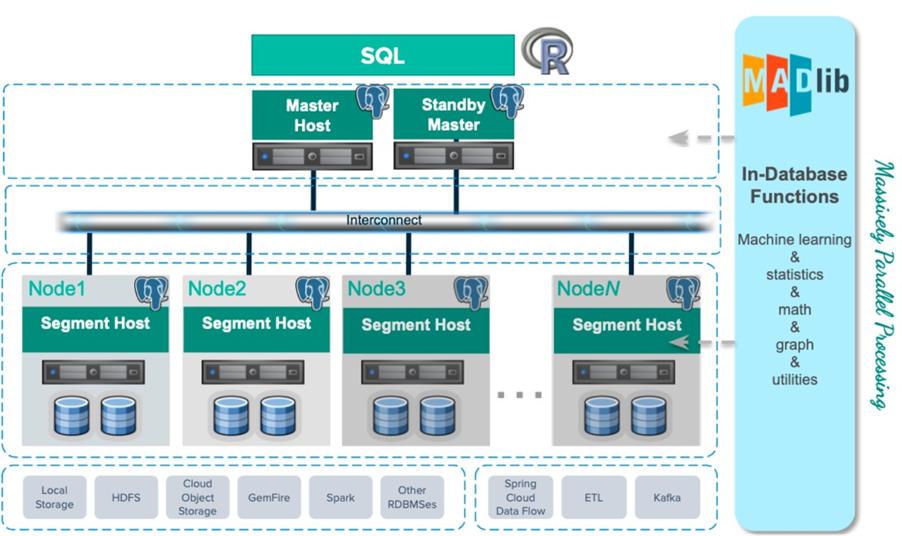
1.架構介紹
Greenplum 是基於 PostgreSQL 一種大規模並行處理 (MPP) 資料庫伺服器,其架構專門設計用於管理大規模分析資料倉儲和商業智能負載,透過在多個伺服器或主機之間分配負載來存儲和處理大量資料並支援標準的資料庫應用程序接口,例如 ODBC 和 JDBC,用戶可以創建他們自己的客戶端應用程序來連接到 Greenplum 資料庫。
2.運作機制
Greenplum 將資料和工作負載分配到不同的伺服器或主機來存儲和處理大量資料。 其中,Master node 是 Greenplum Database 系統的入口點,負責接受用戶連線、SQL 指令及存放 Metadata 資料。Master node 協調多個 Segment node 的 Database 來執行資料處理和儲存,Segment node 之間彼此各自獨立並儲存一部分資料,而各 Segment node 透過 Greenplum Database 內部網路層與其他 Segment node 及 Master node 相互傳遞訊息。
當 Master node 處理 SQL 指令時,將其解析、計劃並分派到所有的 Segment node 來執行指令,並返回請求的資料內容或將結果寫入到資料庫中。
3.資料穩定性
每個資料表根據用戶在資料定義語言 (DDL) 中指定的分佈鍵 (Distribution key) 劃分成多個 Segment。對於每份資料,各有一個 Primary 和 Mirror,分別存放於不同的 Segment node 上,以確保單一主機故障發生時仍能訪問該資料而能不間斷地提供服務。
4.儲存格式與高可用性
Greenplum 除引用 PostgreSQL 的 Heap 資料儲存格式之外,也為了資料倉儲中大型的資料表,而新增 Append-Optimized(AO) 資料儲存格式,除了一般的資料儲存格式外,也提供列儲存 (AORO) 和行儲存 (AOCO),並且支援對資料進行壓縮。
此外,可透過啟用 Hardware level RAID、啟用檢查資料儲存 checksums、新增 Segment 的資料鏡像備份、啟用 Master node HA 機制、雙 Clusters 機制與資料同步等, Greenplum 能提供高可用架構及完整的故障轉移機制。
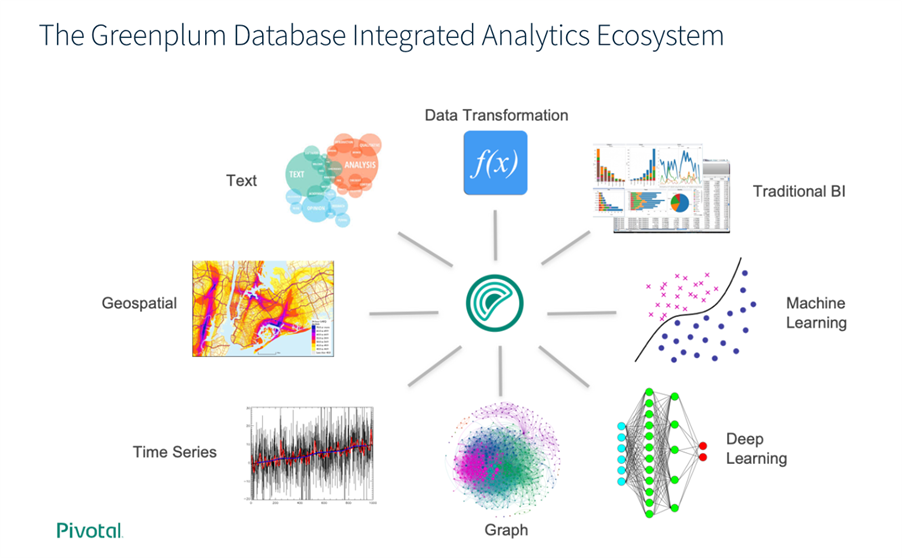
5.整合分析生態圈
Greenplum 為資料科學家、資料架構師和業務、決策者提供了一個理想的框架,以探索人工智慧、機器學習、深度學習、文本分析和地理空間分析。
如下圖為 Greenplum 整合分析生態圈。
圖片出處:Pivotal Greenplum
6.分析優勢
Greenplum 採用 In-Database Analytics 並提供不同的分析工具。其中 MADlib Extension 提供了在 Greenplum 資料庫中運行機器學習和深度學習工作負載的能力,並支援結構化 SQL 查詢語言在 Greenplum 資料庫引擎中進行平行運算,無需與其他工具之間傳輸資料。提供在結構化和非結構化資料上的數學運算、統計、圖形、機器學習和深度學習方法。
Greenplum 分析優勢如下:
- 在單個環境中分析多種資料類型 (結構化、文本、地理空間和圖形) ,資料量可以擴展到 PB 級並運行專為分散性設計的演算法。
- 透過 SQL 運行多種統計、機器學習和圖形方法。
- 透過利用 MPP 架構和 In-Database Analytics 中的並行性,在更短的時間內訓練更多模型。
- Greenplum 平台擴展框架 (PXF) 的功能,它提供了Connector,使您能夠訪問存儲在 Greenplum 資料庫部署外部來源中的資料,包含 HDFS、Hive、HBase。
- 支援 GPU 加速在深度學習演算法的運算,如 Keras 和 TensorFlow 。
- Greenplum PL/Container 實現將執行程式與主機操作系統隔離的容器,為不同的使用者提供獨立的分析環境並進行資源控管。
- 使用 R、Python、Java 等語言開發客製化分析,並在整個集群中分散式的執行。
透過 ODBC、JDBC 方式與 BI 工具整合,包括 SAS、IBM Cognos、SAP Analytics Solutions、Qlik、Tableau、Apache Zeppelin 和 Jupyter等。
7.系統監控
在系統監控方面,Greenplum 提供系統指令,如:gpstate、gplogfilter,可即時判斷系統有無相關異常。同時也能透過監控 Greenplum 系統資料表,如:gp_toolkit 查看硬碟使用空間、gp_internal_tools 查看現況連線記憶體使用率、gp_segment_configuration 查看各節點狀態、gp_master_mirroring 測試 Mirror 狀況等,以定期追蹤系統營運變化資訊。此外,也能透過自行新增對硬體與系統相關監控,如:硬碟使用空間、網路連線、RAID 檢查等對整體系統服務做更精確的偵測與告警。
8.備份還原
Greenplum 提供備份及還原功能,可透過 PostgreSQL 指令如 pg_dump、pg_dumpall、pg_restore 與 Greenplum 指令 COPY TO 來達成。
Greenplum官方說明文件功能整理
1.支援分散式儲存系統及大量平行處理(Massively Parallel Processing)。
Greenplum Database 是基於 PostgreSQL 一種大規模並行處理 (MPP) 資料庫伺服器,其架構專門設計用於管理大規模分析資料倉庫和商業智能負載,將資料分散到多個伺服器上。
每組 Greenplum 叢集由一個 Master node、Standby node 和 Segment node 組成。Master node 為資料庫的入口點,提供連線、SQL 查詢及存放目錄資料,而 Segment node 則存放所有資料資料。
Segment node 彼此各自獨立的,每個 Segment node 存儲一部分資料,負責大部分查詢的處理。對於每個 Segment 的內容,都有一個 Primary 和 Mirror,它們在不同的主機上運行。
當一個查詢進入 Master node 時,當被解析、計劃並分派到所有的 Segment node 來執行查詢計劃,並返回請求的資料或將查詢結果寫入到資料表中。
2.相容於開放資料庫互連(ODBC)及Java資料庫連線(JDBC)存取方式。
Greenplum 支援標準的資料庫應用程序接口,例如 ODBC 和 JDBC,用戶可以創建他們自己的客戶端應用程序來連接到 Greenplum 資料庫。此外,psql 客戶端應用程序為 Greenplum 資料庫提供的一個交互式命令行界面。
3.支援結構化查詢語言(SQL)、機器學習及統計分析作業。
Greenplum MADlib Extension 提供了在 Greenplum 資料庫中運行機器學習和深度學習工作負載的能力。MADlib Extension 支援結構化 SQL 查詢語言在Greenplum 資料庫引擎中進行平行運算,無需和其他工具之間傳輸資料。提供在結構化和非結構化資料上的數學運算、統計、圖形、機器學習和深度學習方法。提供在結構化和非結構化資料上的數學運算、統計、圖形、機器學習和深度學習方法。
https://docs.vmware.com/en/VMware-Tanzu-Greenplum/6/greenplum-database/GUID-analytics-madlib.html
5.支援GPU加速運算與深度學習框架(如Keras、TensorFlow)。
Greenplum 支援 Apache MADlib 套件以提供各種深度學習,如:訓練模型、評估、驗證。
Keras 和 TensorFlow 等深度學習函式庫部署在 Greenplum 的 Segment 節點上,GPU 同時也部署在 Segment 節點上,每個節點上的 Segment 可共享 GPU 執行資訊。透過這樣的架構設計能消除 Segment 和 GPU 之間的傳輸延遲,每個 Segment 只需要處理本機資料得出結果即可,Greenplum 透過 Apache MADlib 將 Segment 的模型參數合併後得到最終的分析模型。
https://tanzu.vmware.com/content/engineers/gpu-accelerated-deep-learning-on-greenplum-database
6.支援資料儲存處理、資料查詢優化建議及記憶體內處理(In-Memory Processing)。
7.針對系統異常狀況提供偵測與告警。
Greenplum 提供系統指令,如:gpstate、gplogfilter,以即時判斷系統有無相關異常。同時也能透過監控 Greenplum 系統資料表,如:gp_toolkit 查看硬碟使用空間、gp_internal_tools 查看現況連線記憶體使用率、gp_segment_configuration 查看各節點狀態、gp_master_mirroring 測試,以定期追蹤系統營運變化資訊。此外,也能透過自行新增對硬體與系統相關監控,如:硬碟使用空間、網路連線、RAID 檢查等對整體系統服務做更精確的偵測與告警。
8.提供權限控管及稽核(Audit)紀錄。
Greenplum 透過設定 Role 提供各帳號、群組的權限控管。Role 可以擁有自己的資料庫物件,也可以給予其他 Role 其存取權限。而 Role 也可以被指定至另一個 Role 中並繼承該 Role 的權限。
Greenplum 紀錄系統啟訖、執行失敗的 SQL、登入與斷線等相關稽核紀錄,也可進一步設定選項來取得各種 SQL 執行的相關細節。稽核紀錄以 CSV 檔案格式各自存放於各節點上,除了查看檔案取得紀錄外,並能透過 SQL 查詢取得。
9.提供高可用架構及故障移轉(Failover)機制。
透過啟用 Hardware level RAID、啟用檢查資料儲存 checksums、啟用子節點資料鏡像、啟用主節點 HA 機制、雙 Clusters 機制與資料同步等 Greenplum 功能提供高可用架構及故障移轉機制,並提供監控執行緒來確保系統服務的完整性。
10.提供備份(Backup)與還原(Recovery)功能。
Greenplum 提供平行式與非平行式的備份及還原功能。平行式將備份存放在各子節點中,可透過 Greenplum 指令 gprestore、gpbackup 來達成;而非平行式透過網路與硬體 IO 寫入主節點的本地存儲,可透過 Postgres 指令 pg_dump、pg_dumpall、pg_restore 與 Greenplum 指令 COPY TO 來達成。
https://docs.vmware.com/en/VMware-Tanzu-Greenplum-Backup-and-Restore/index.html
訂閱偉康科技洞察室部落格,掌握最新科技趨勢!
專人協助
由偉康業務人員為您詳細說明偉康的解決方案,以及相關產業經驗。