如何使用Elasticsearch以自然語言提示ChatGPT

最近大家都在談論ChatGPT。這個大型語言模型(LLM)的一項很酷的功能是有產生程式碼的能力。我們可以使用它來在 Elasticsearch DSL 查詢。像是在 Elasticsearch 中搜尋使用「給我2017年股票指數的前10個文件」這樣的句子在Elasticsearch®中進行搜索。這個實驗顯示了這是可能的,但有一些限制。在這篇文章中,我們描述了這個實驗以及我們為這個案例發布的開源庫。
ChatGPT能夠生成Elasticsearch DSL嗎?
我們開始了一些測試,專注於ChatGPT生成Elasticsearch DSL查詢的能力。為此,您需要向ChatGPT提供一些有關您想搜索的數據結構的上下文。
在Elasticsearch中,數據儲存在索引中,這類似於關係數據庫中的「表」。它有一個對映,定義了多個字段及其類型。因此我們需要提供想要查詢的索引對映資訊。透過這樣做,ChatGPT就有了將查詢轉換為Elasticsearch DSL的必要上下文。
Elasticsearch提供了一個get mapping API來檢索索引的對映。在我們的實驗中,我們使用了一個這裡提供的股票指數數據集。這個數據集包含了五年的500家財富公司的股票價格,從2013年2月到2018年2月。
這裡我們報告了包含數據集的CSV文件的前五行:
date,open,high,low,close,volume,name
2013-02-08,15.07,15.12,14.63,14.75,8407500,AAL
2013-02-11,14.89,15.01,14.26,14.46,8882000,AAL
2013-02-12,14.45,14.51,14.1,14.27,8126000,AAL
2013-02-13,14.3,14.94,14.25,14.66,10259500,AAL每一行包含股票的日期、當日開盤價、最高和最低價值、收盤價、交易量,最後是股票名稱,例如美國航空集團股份有限公司(AAL)。
與股票指數相關聯的對應如下所示:
{
"stocks": {
"mappings": {
"properties": {
"close": {"type":"float"},
"date" : {"type":"date"},
"high" : {"type":"float"},
"low" : {"type":"float"},
"name" : {
"type": "text",
"fields": {
"keyword":{"type":"keyword", "ignore_above":256}
}
},
"open" : {"type":"float"},
"volume": {"type":"long"}
}
}
}
}我們可以使用 GET /stocks/_mapping API 從 Elasticsearch 中檢索對映。
讓我們建立一個提示來找出答案
為了將以人類語言表達的查詢轉換為 Elasticsearch DSL,我們需要找到合適的提示來提供給 ChatGPT。這是整個過程中最困難的部分:實際上使用正確的問題格式(正確的提示)來編程 ChatGPT。
在經過一些迭代後,我們最終得到了以下看似效果良好的提示:
Given the mapping delimited by triple backticks ```{mapping}``` translate the text delimited by triple quotes in a valid Elasticsearch DSL query """{query}""". Give me only the json code part of the answer. Compress the json output removing spaces.在提示中,{mapping} 和 {query} 是兩個佔位符,需要用對映的 JSON 字符串(例如,前面示例中使用 GET /stocks/_mapping 返回的)和以人類語言表達的查詢(例如:返回 2017 年的前 10 個文件)替換。
當然,ChatGPT 有其限制,在某些情況下可能無法回答問題。我們發現,大多數情況下,這是因為提示中使用的句子過於一般或含糊不清。為了解決這種情況,我們需要加強提示的細節。這個過程稱為迭代,需要多個步驟來定義要使用的正確句子。
如果您想要試試 ChatGPT 如何將搜索句子翻譯為 Elasticsearch DSL 查詢(甚至是 SQL),您可以使用 dsltranslate.com。
將所有內容整合起來
我們將 OpenAI 提供的 ChatGPT API 與 Elasticsearch API(用於對映和搜索)結合在一起,開發了一個用於 PHP 的實驗庫。
該庫提供了一個具有以下 API 的 search() 函數:
search(string $index, string $prompt, bool $cache = true)其中,$index 是要使用的索引名稱,$prompt 是以人類語言表達的查詢,而 $bool 是一個可選參數,用於使用緩存(默認情況下啟用)。
該函數的運行過程如下圖所示:
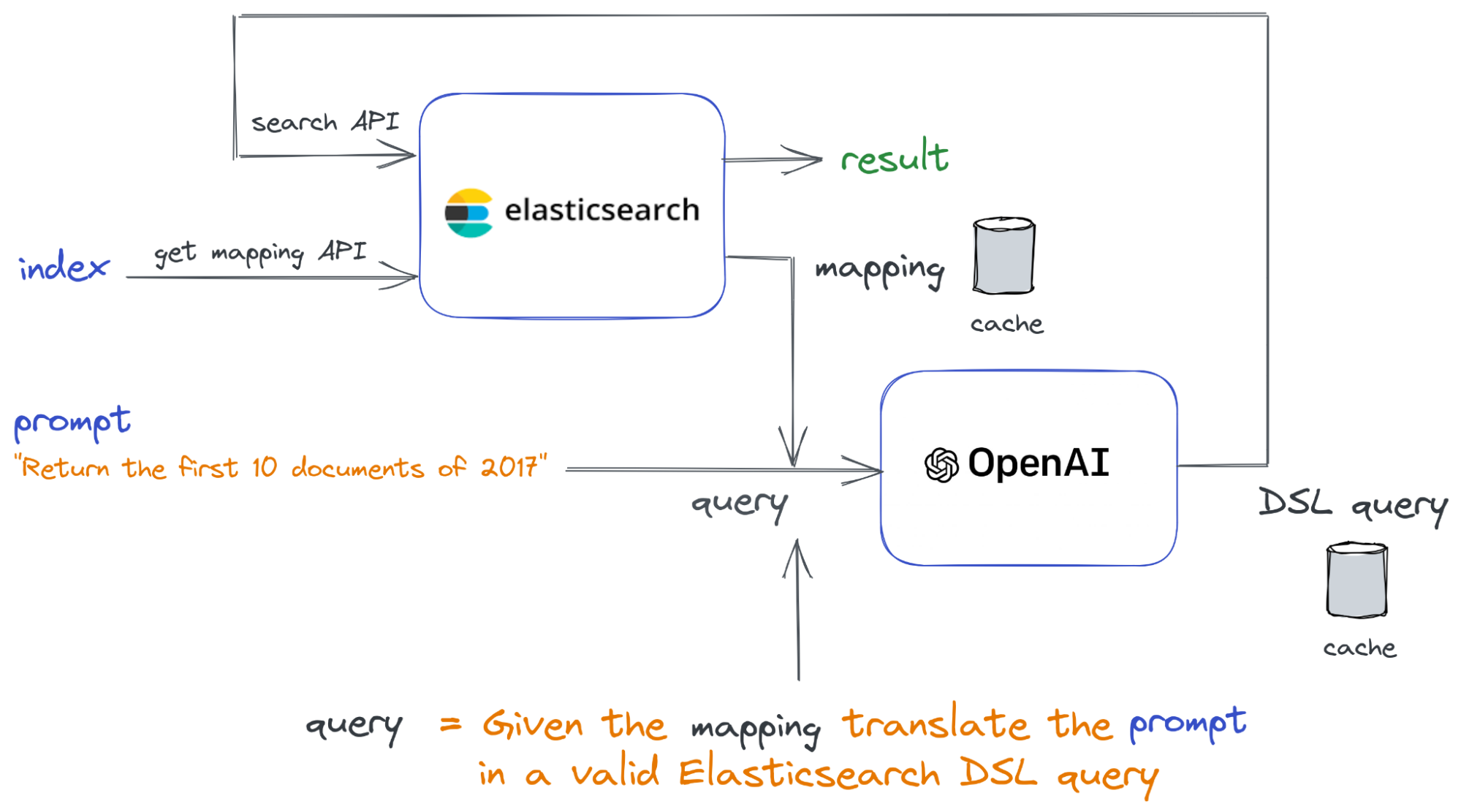
輸入為索引和提示(位於左側)。索引用於從Elasticsearch檢索對映(使用get mapping API)。結果是一個JSON格式的對映,用於構建要發送到ChatGPT的查詢字符串,使用以下API代碼。我們使用的是OpenAI的gpt-3.5-turbo模型,它能夠將文本翻譯成程式碼。
從ChatGPT得到的結果包含一個Elasticsearch DSL查詢,我們用它來查詢Elasticsearch。然後將結果返回給用戶。為了查詢Elasticsearch,我們使用了官方的elastic/elasticsearch-php客戶端。
為了優化回應時間並降低使用ChatGPT API的成本,我們使用了一個基於文件的簡單緩存系統。我們使用緩存來:
- 儲存Elasticsearch返回的對映JSON:我們將這個JSON儲存在以索引命名的文件中。這樣可以讓我們在不需要向Elasticsearch進行額外調用的情況下檢索對映資訊。
- 儲存由ChatGPT生成的Elasticsearch DSL:為了緩存生成的Elasticsearch DSL,我們使用提示的哈希(MD5)來命名緩存文件。這種方法使我們能夠重用先前為相同查詢生成的Elasticsearch DSL,消除了再次調用ChatGPT API的需求。
我們還添加了透過getLastQuery()函數以程式化方式檢索Elasticsearch DSL的可能性。
使用金融數據運行實驗
我們使用Elastic Cloud來儲存這裡報告的股票價值。具體來說,我們使用了一個簡單的批量腳本來讀取CSV格式的股票文件,並使用批量API將其發送到Elasticsearch。
有關如何設置Elastic Cloud和檢索API密鑰的更多詳細資訊,請閱讀文檔。
一旦我們儲存了股票索引,我們就使用了一個簡單的PHP腳本來測試用英文表達的一些查詢。我們使用的腳本是examples/test.php。
要執行這個examples/test.php腳本,我們需要設置三個環境變量:
- OPENAI_API_KEY:OpenAI的API密鑰
- ELASTIC_CLOUD_ENDPOINT:Elasticsearch實例的URL
- ELASTIC_CLOUD_API_KEY:Elastic Cloud的API密鑰
使用股票對映,我們測試了以下查詢,並記錄了所有的Elasticsearch DSL回應。
Query: Return the first 10 documents of 2017
Result:
{
"query":{
"range":{
"date":{
"gte":"2017-01-01",
"lte":"2017-12-31"
}
}
},
"size":10
}Query: Return the first 30 names of all the different stock names
Result:
{
"size":0,
"aggs":{
"unique_names":{
"terms":{
"field":"name.keyword",
"size":30
}
}
}
}Query: Return the max value of the field "high" for each stock in 2015
Result:
{
"aggs":{
"stocks":{
"terms":{"field":"name.keyword","size":100},
"aggs":{
"max_high":{"max":{"field":"high"}}
}
}
},
"query":{
"bool":{
"must":[{
"range":{
"date":{
"gte":"2015-01-01",
"lt":"2016-01-01"
}
}
}]
}
}
}Query: Return the average value of the field "high" for each stock in 2015
Result:
{
"size":0,
"aggs":{
"stocks":{
"terms":{
"field":"name.keyword",
"size":10000
},
"aggs":{
"2015":{
"filter":{
"range":{
"date":{
"gte":"2015-01-01",
"lt":"2016-01-01"
}
}
},
"aggs":{
"avg_high":{
"avg":{
"field":"high"
}
}
}
}
}
}
}
}Query: Return the max value of the field "high" for all the documents with name MON in 2014
Result:
{
"query":{
"bool":{
"must":[
{
"match":{
"name.keyword":"MON"
}
},
{
"range":{
"date":{
"gte":"2014-01-01",
"lt":"2015-01-01"
}
}
}
]
}
},
"size":0,
"aggs":{
"max_high":{
"max":{
"field":"high"
}
}
}
}正如您所看到的,結果非常好。最後一篇關於封閉場地和開放場地的差異令人印象深刻!
所有請求均已翻譯為有效的 Elasticsearch DSL 查詢,該查詢根據以自然語言表達的問題是正確的。
使用您所說的語言!
ChatGPT 的一個非常好的功能是能夠用不同的語言指定問題。
這意味著您可以使用此程式庫並以不同的自然語言指定查詢,例如義大利語、西班牙語、法語、德語等。
這是一個例子:
# English
$result = $chatGPT->search('stocks', 'Return the first 10 documents of 2017');
# Italian
$result = $chatGPT->search('stocks', 'Restituisci i primi 10 documenti del 2017');
# Spanish
$result = $chatGPT->search('stocks', 'Devuelve los 10 primeros documentos de 2017');
# French
$result = $chatGPT->search('stocks', 'Retourner les 10 premiers documents de 2017');
# German
$result = $chatGPT->search('stocks', 'Senden Sie die ersten 10 Dokumente des Jahres 2017 zurück');先前的所有搜尋都有相同的結果,產生以下 Elasticsearch 查詢(或多或少):
{"size":10,"query":{"range":{"date":{"gte":"2017-01-01","lt":"2018-01-01"}}}}在這篇文章中,我們介紹了使用ChatGPT將自然語言搜索句子轉換為Elasticsearch DSL查詢的實驗案例。我們開發了一個簡單的PHP庫,使用OpenAI API在幕後進行查詢翻譯,同時提供了緩存系統。
實驗的結果很有前景,即使答案的正確性存在限制。儘管如此,我們肯定會進一步研究使用ChatGPT以及其他越來越受歡迎的LLM模型,以自然語言查詢Elasticsearch的可能性。
訂閱偉康科技洞察室部落格,掌握最新科技趨勢!
專人協助
由偉康業務人員為您詳細說明偉康的解決方案,以及相關產業經驗。