Neo4j匯入CSV與情境查詢-上
Posted On 2022 年 3 月 7 日


*以上資料姓名隨意發想及北市高中地址、電話,如有雷同純屬巧合。
如果你是硬派男子漢,想要直接透過路徑去打開資料夾的話...以下方法提供給你參考
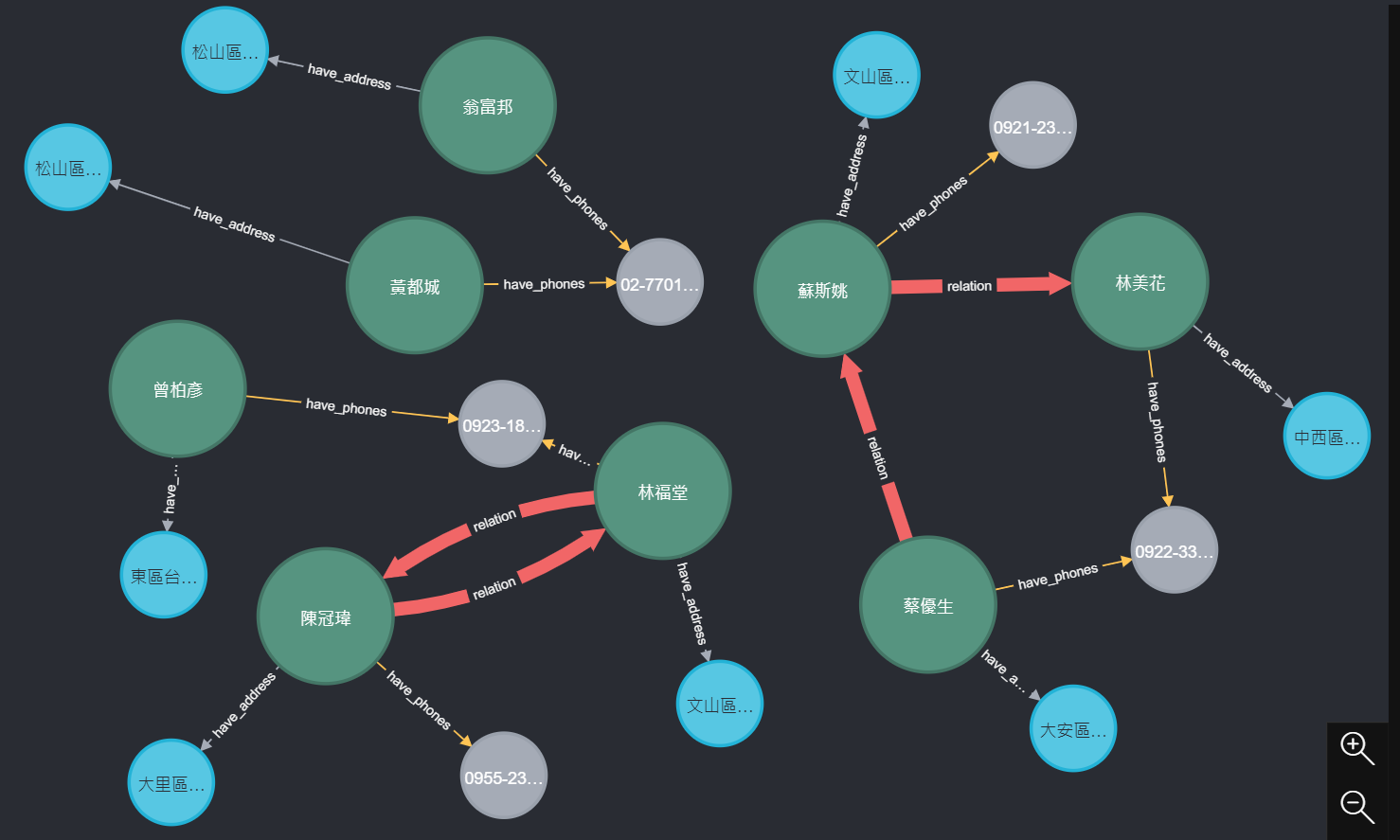
錯誤的關聯結果
貼心的再給你看一次原始資料
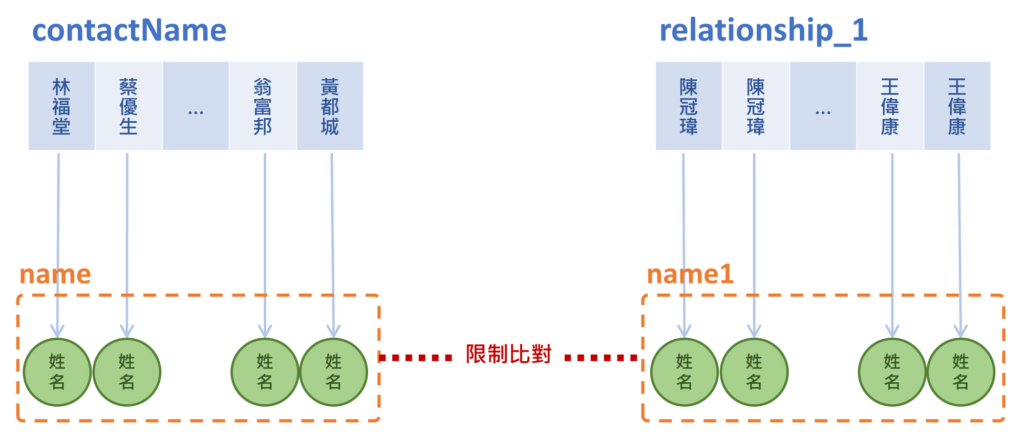
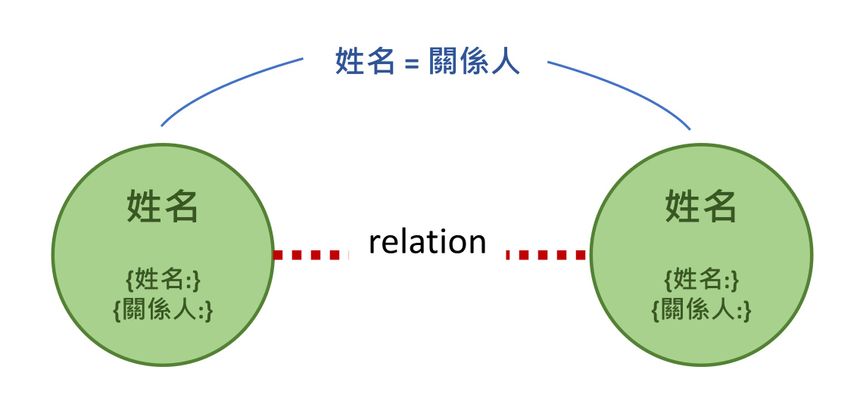
情境關聯示意圖
*以上資料姓名隨意發想及北市高中地址、電話,如有雷同純屬巧合。
如果你是硬派男子漢,想要直接透過路徑去打開資料夾的話...以下方法提供給你參考
錯誤的關聯結果
貼心的再給你看一次原始資料
情境關聯示意圖