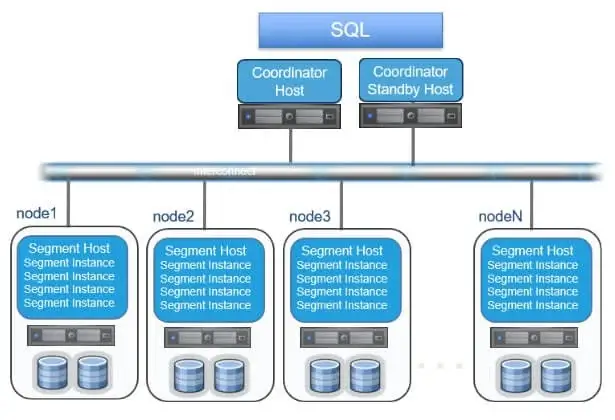
 Coordinator Host 與用戶連接並協調
Coordinator Host 與用戶連接並協調
與Segment Hosts的工
Segment Hosts管理數據和行程查詢
Segment Hosts有自己的 CPU、磁碟和
記憶體(不共用任何內容)
用於數據處理連續管道的高速互連

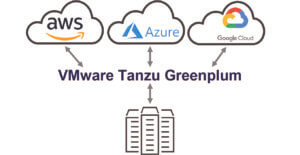
部署在任一處
基於開源科技的應用
部署在任一處
▪在客戶數據中心或公共雲中運行
▪虛擬或Bare-mental
▪基於開放標準(Commodity Hardware)的硬體運行,無需專有硬體設備
基於開源科技的應用
▪透過大型Greenplum Community社群取得更快的功能添加
▪獨立供應商
▪基於 Postgresql 的核心技術, 擁有強大的社群支援



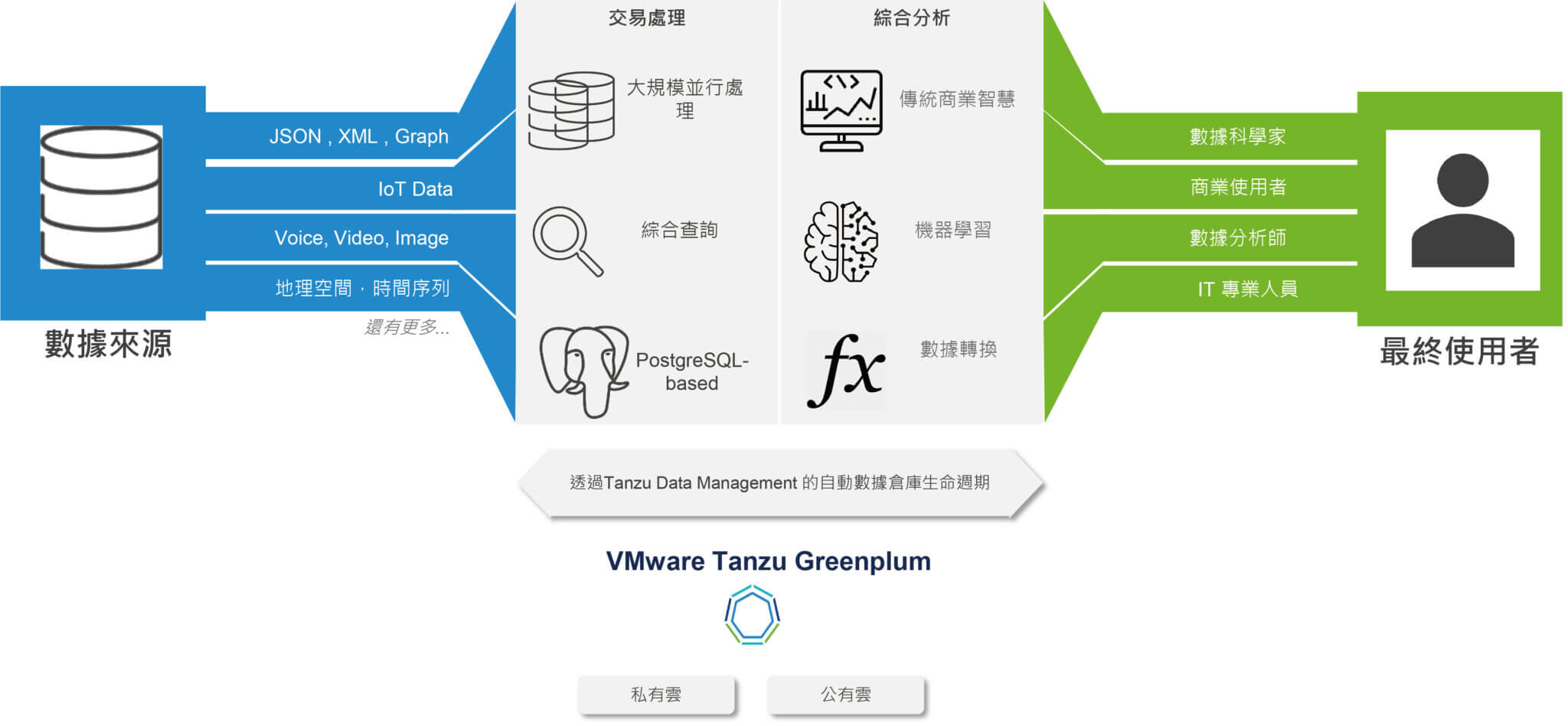
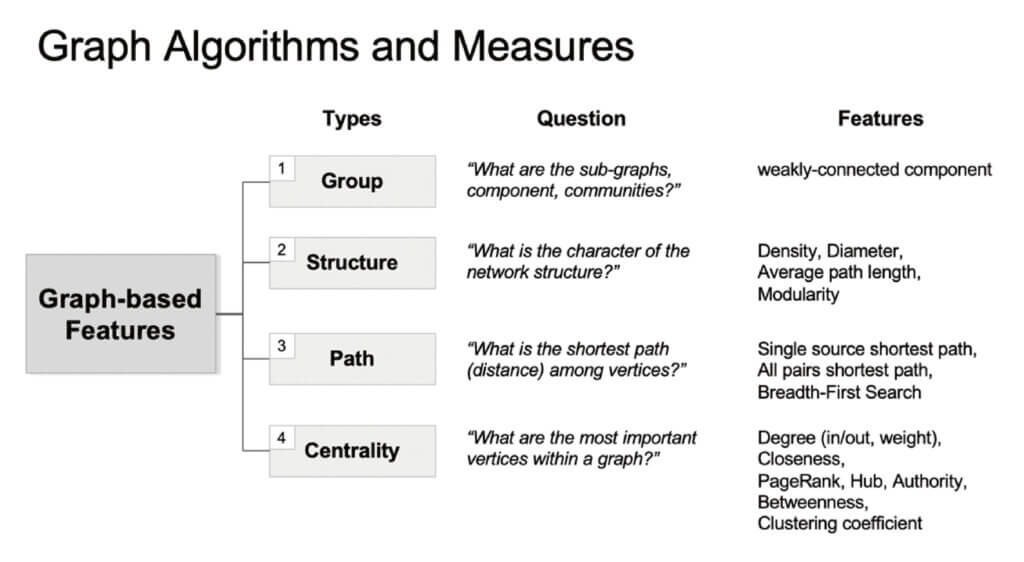
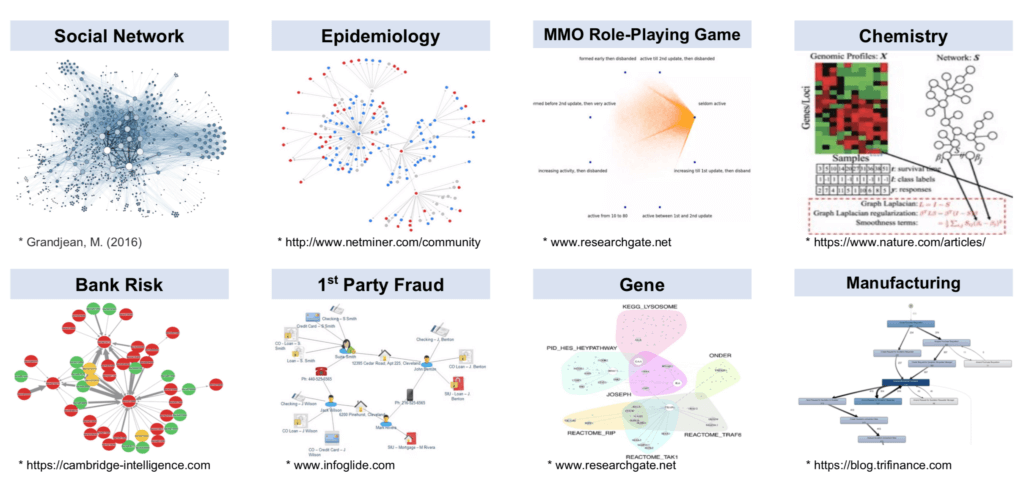
企業圖形數據的TB和PB等級分析
利用GPU加速訓練複雜神經網路
存儲、搜索和分析地理座標
對非結構化數據進行索引、搜索和分析
在流行的程式設計語言中使用自定義的邏輯進行擴展分析
企業圖形數據的TB和PB等級分析

利用GPU加速訓練複雜神經網路
▪訓練神經網路
使用圖像和文本等非結構化數據,並讓 Greenplum訓練模型去辨識物體
▪MPP 比例性能
使用Greenplum的計算網格訓練和比較數千種型號
▪Tensor Flow, Keras, GPUs
使用AI的常用套件,而模型的複雜性則由Greenplum 使用者自行管理

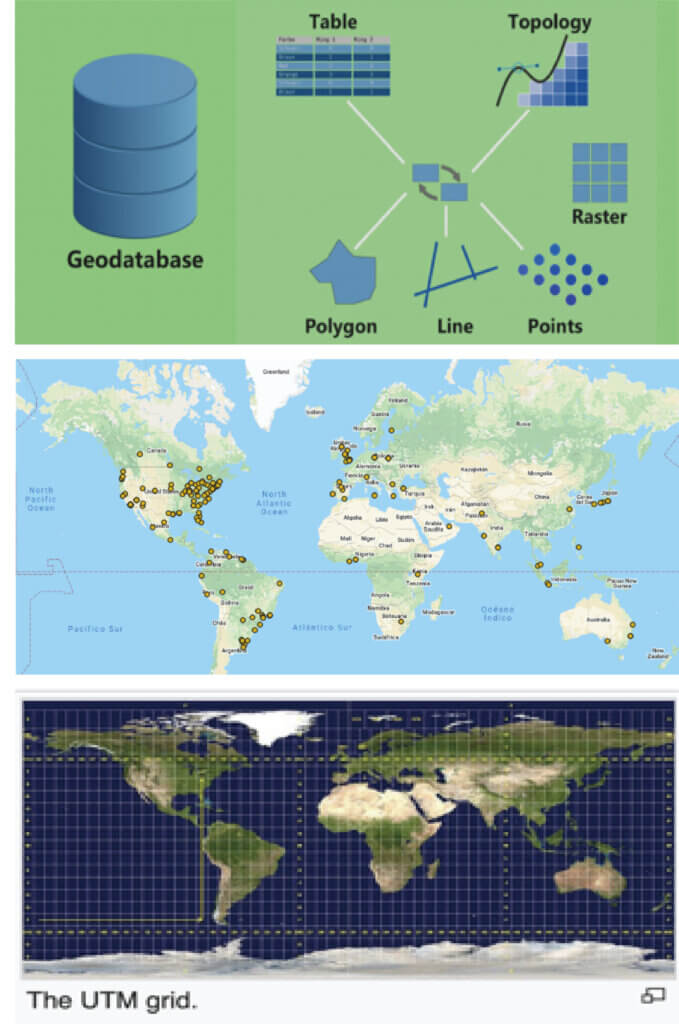
存儲、搜索和分析地理座標
將大數據資料庫轉換為 Geo 資料庫,以便根據位置存儲、搜索和分析數據
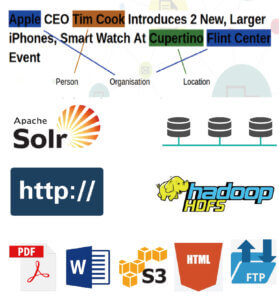
對非結構化數據進行索引、搜索和分析
▪將二進位數據或常人可讀的格式數據提取成機器能夠理解或操作的數據。
▪Index the text data,以便我們可以快速搜索特定的文本和文檔。
▪搜尋 在文字中的關鍵字或規律。
▪分析文本的真正含義。
在流行的程式設計語言中使用自定義的邏輯進行擴展分析
Server 端功能
▪逐行處理數據
▪大規模並行模型執行
▪使用程序語言轉換每一行
▪在需要時通過容器化執行提供安全性
▪導入OSS庫以獲取高級功能(例如NLTK)
▪導入企業庫以訪問您的專有邏輯代碼
▪用戶定義的匯總分組
▪調用OSS機器學習算法