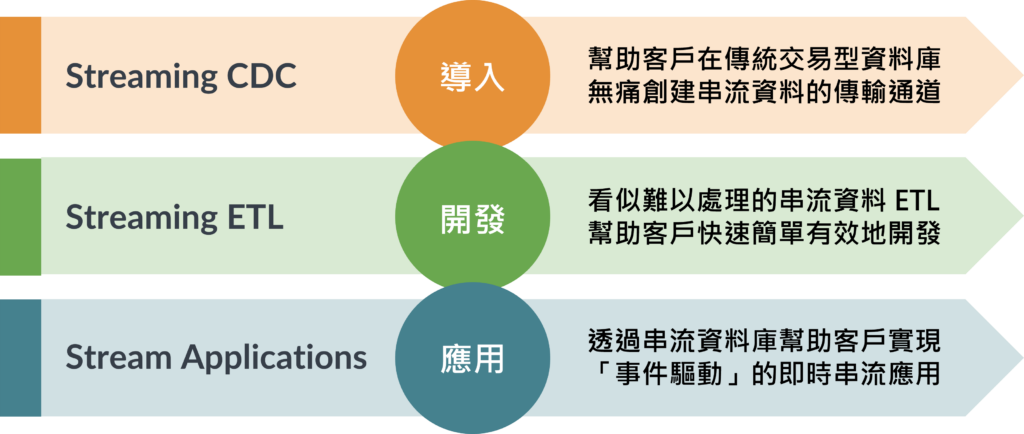
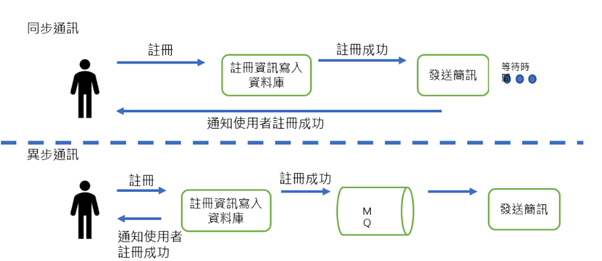
Confluent Kafka Why Streaming ? 「資料來源複雜」難以整合嗎? 「資料時效性短暫」需要動態更新嗎? 「資料分析非即時」錯失行銷良機嗎? 「系統服務異常」只能後知後覺嗎? 資料串流平台 即時整合異質資料 即時追蹤資料變化 即時分析智能行銷 即時監測系統異常 應用服務提供 提供服務創造商機商業活動創造資料 巨量資料收集 資料用戶快速增長資料量級倍數成長 批量資料分析 批次資料處理分析非即時的資料應用 即時串流應用 極近實時資料處理智能分析快速決策 Why Confluent ? 優於原生Kafka的企業級工具包,提升串流資料平台的可用性及降低技術導入門檻 發展具有高擴展、高性能和高可靠性的新世代事件驅動應用數據管道 Developer •支援多種開發語言 ( Java, C#, Python, Go… ) •提供120+種Kafka連接器串連異質平台 •大幅提升串流資料整合開發效率 Availability •高度彈性的部署模式 •支援Bare-metal或容器化 •企業級自動化容錯高可用性 Security •企業級身分驗證機制整合 •企業級資料加密防護 •資安漏洞高效修補 Management •Web介面一站式管理監控 •串流資料內容結構即時性查詢 •平台元件集中化管理及健康度監測 Why WebComm ? Kafka介紹 Kafka 會取用串流資料並準確記錄發生的情況和時間,這項記錄稱為不可變的修訂版本記錄。這是不可變的內容,因為只能附加而不能更改。在這個系統中,可以存取資料,也可以從任意數量的串流即時應用程式和其他系統新增更多資料。像是,使用Kafka 在網站上所有交易資料串流送至應用程式,這應用程式會即時追蹤產品銷售,並將庫存產品數量進行比對,就能即時補充庫存。Apache Kafka 是一個開源分佈式事件流平台,被數千家公司用於高性能數據管道、流分析、數據集成和關鍵任務應用程序。 什麼是Kafka? Kafka 是一個事件串流平台,主要用於收集、處理和儲存串流事件資料或是沒有明確開始或結束的資料。 Kafka 有助於建構新一代的分散式應用程式,應用程式能夠彈性擴充,每分鐘可處理多達數十億個串流事件。資料處理通常是透過週期性的批次工作進行,也就是會先儲存原始資料,之後再每隔一段時間處理。 在尚未有Kafka 前,資料處理通常是以週期性的批次工作進行,先儲存原始資料,之後每隔一段時間再處理。Kafka 事件串流能夠即時處理持續湧進的事件串流,而在從中擷取資料的時間中並建立推送的應用程式,當只要發生需要關注的事情,推送應用程式就會進行採取行動。 事件串流有哪些例子 1.連續分析顧客網頁應用程式所產生的紀錄檔2.監控並回應顧客瀏覽電子商務網站時的行為3.透過分析社群網路產生的點擊流量資料持續掌握顧客喜好 4.收集後回應由物聯網(IoT)裝置產生的資料 哪些企業使用Kafka? Kafka好處 1.開放的原始碼系統2.擴充性快速-可以隨著不斷增加的資料量進行擴充,可即時提供資料-可以將處理程序分散在多台實體機或虛擬機中-可以向外擴充,機器故障情況但平台依然能運行 Kafka功能 訊息佇列(message queue):Kafka 是一個基於生產/消費模式的MQ,主要用於大數據即時處理。生產/消費模式:可能有多個數據收集系統,同時將不同來源的日誌送入 kafka 中,此稱為生產者,但是使用資料者則只會訂閱自己感興趣的資料來做使用,此稱為消費者。分散式事件流平台:Kafka 除了 MQ 以外也被許多的公司拿來作為data pipeline, stream analysis, data aggregation 的用途。 Kafka如何運作 發布 -> 取用 -> 處理 -> 連結 -> 儲存 1.發布: 可將資料來源利用資料事件串流發布或放置到一或多個 Kafka 主題,集合類似資料事件的群組。例如:您可以從 IoT 裝置 (譬如網路路由器) 取用資料串流,然後進行預測的維護應用程式中,計算該路由器何時可能會發生故障的問題。 2.取用: 可以從一個或多個 Kafka 主題中取用資料,然後處理產生的資料串流。例如:應用程式可以從多個社群媒體串流中取用資料並進行分析,判斷網路上對某個品牌的討論趨勢。 3.處理: Kafka Streams API 可以當串流處理器,再從一個或多個主題取用傳入的資料串流,接著產生資料串流後傳出至一或多個主題。 4.連結: 可以建立可重複使用的生成器或取用器連線,將 Kafka 主題連結到現有應用程式。目前有數百種現成的連接器可供使用,包括可連結 Dataproc、BigQuery 等主要服務的連接器。 5.儲存: Apache Kafka 提供儲存服務。Kafka 可以做為「可靠資料來源」,將資料分散在多個節點,在單一資料中心內或橫跨多個可用區,都可部署。 Kafka的應用場景 -解耦- -異步通訊- -流量緩存- 更多相關內容 了解更多數據湖泊管理平台 > 了解更多 Elastic Stack > 專人協助 由偉康業務人員為您詳細說明偉康的解決方案及相關產業經驗 02-7701-5899 service@webcomm.com.tw 聯絡我們 專人協助 由偉康業務人員為您詳細說明偉康的解決方案及相關產業經驗 02-7701-5899 service@webcomm.com.tw 聯絡我們 台北總公司 +886 2 7701-5899105409 台北市松山區南京東路五段161號3樓聯絡我們 : service@webcomm.com.tw 解決方案 智慧資安 智能決策 資安加值服務 智能加值服務 最新消息 專業團隊 ESG與永續發展 影片介紹 策略結盟 加入我們 投資人專區 公司概況 財務資訊 投資人關係 新聞中心 聯絡我們 Facebook-f Linkedin Youtube 偉康科技股份有限公司 版權所有 © 2024 WebComm Technology Co., Ltd. All Rights Reserved.隱私權政策 台北總公司 +886 2 7701-5899105409 台北市松山區南京東路五段161號3樓聯絡我們 : service@webcomm.com.tw 解決方案 智慧資安 智能決策 資安加值服務 智能加值服務 最新消息 專業團隊 ESG與永續發展 影片介紹 策略結盟 加入我們 投資人專區 公司概況 財務資訊 投資人關係 新聞中心 聯絡我們 Facebook-f Linkedin Youtube 偉康科技股份有限公司 版權所有 © 2024 WebComm Technology Co., Ltd. All Rights Reserved.隱私權政策